Case Study - Wander
Testing Wander with traditional tools was impossible


COMPANY
A modern travel platform that pairs the comfort of private vacation homes with luxury-hotel-grade amenities and 24/7 concierge service
INDUSTRY
B2C Travel ($40 Million)
COMPANY SIZE
200
FOUNDED
2021
20×

Increase
in release velocity for any new updates.
$750K
Annual QA spend
avoided after adapting Spur.
80%+

Test coverage achieved
within the first month with 500+ tests daily.
The Problem
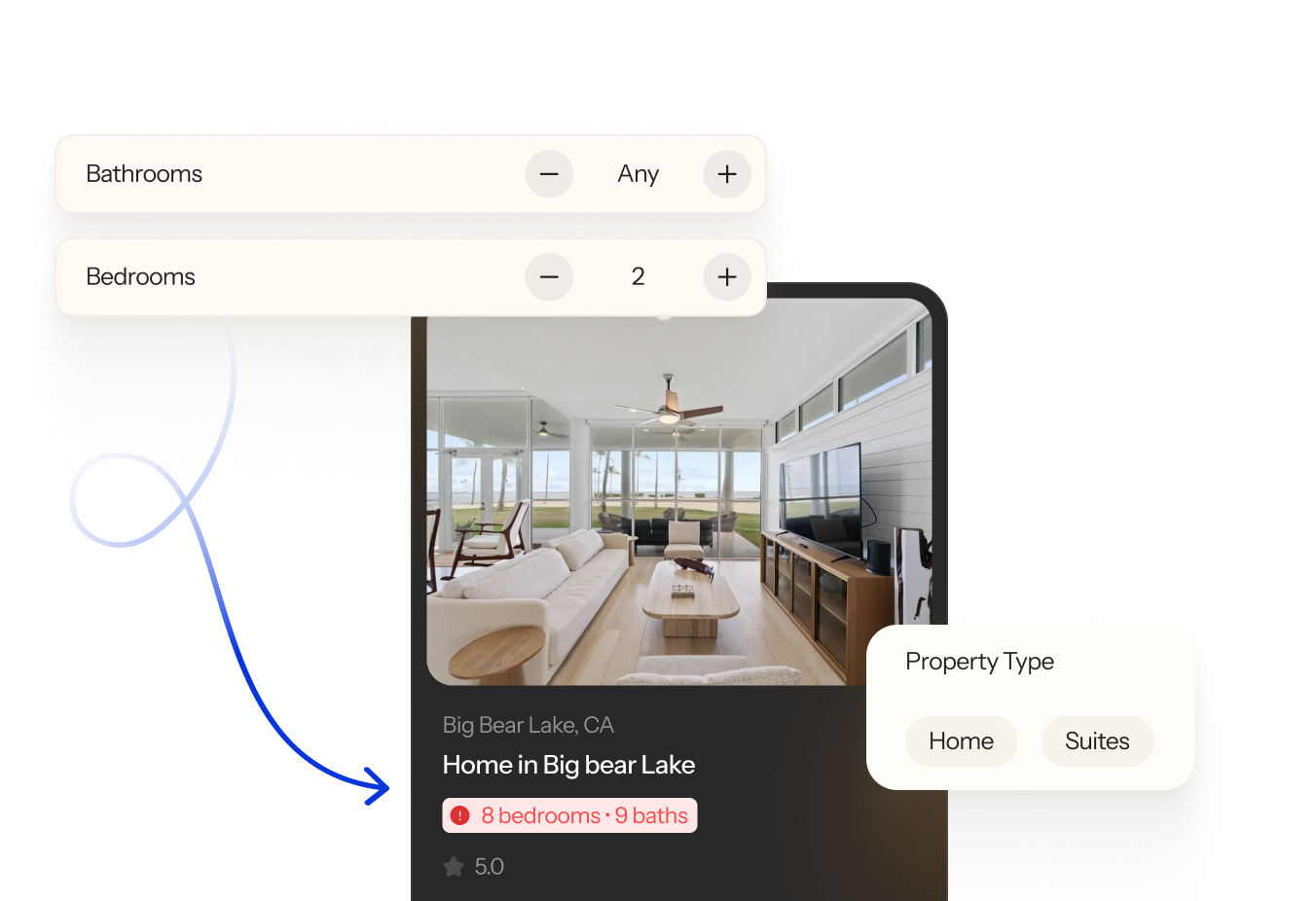
50 filters and 50+ locations. Millions of possible scenarios, and no tool that could handle any of it.
Wander is a luxury travel product, the kind where a broken search result or a misfiring concierge message isn't just a bug, it's a ruined booking experience for someone planning a vacation. The quality bar is high, and the testing surface is enormous.
Search alone has more than 50 filters across 50+ locations. That's millions of possible filter combinations before you even get to the AI layer. Wander's search doesn't just match keywords, it understands natural language queries. "Beachfront homes in NYC," "properties in California with a hot tub," "somewhere quiet on the East Coast." Every query is different. Every result needs to make sense.
Then there's Ava, Wander's AI concierge, who handles bookings, answers questions, and guides users through the platform in natural conversation. Testing Ava means testing something that, by design, never gives exactly the same response twice.
Traditional tools weren't built for any of this. String-based assertions, checking whether a specific word or phrase appears in the output, completely break down when the output is generated by a language model. You can't write "verify the response contains 'beachfront'" when the response is different every time and the point is whether it makes sense, not whether it matches a pattern.
"Spur really allowed us to streamline the testing process and keep up with the pace of the product changes that we were shipping."
Manual testing was the only fallback, and at Wander's scale and pace, it was already failing. QA cycles were taking days. The team was shipping fast and hoping coverage would hold.
The Solution
Writing tests 10× faster, validating AI with AI and getting feedback in minutes.
Maxwell Iheagwara, Wander's Lead QA Engineer, had used Cypress before. He describes the difference plainly: writing Spur tests is more than 10× faster. The reason is specific, with Cypress, you still have to type exact string assertions for everything you want to validate. If a search should return results for "hotels," you have to type: check that the text reads "look for hotel." You can't automatically generate what Spur puts in there.
With Spur, you give a high-level instruction. "Search for a property somewhere in the US." Spur's agent navigates like a real user, generates a natural search query, "properties in California," "beachfront homes in New York," something different each run, and then validates whether the results actually make sense, not just whether they contain a specific string.
"Writing Spur tests is more than 10× faster than traditional automation with Cypress."
That non-determinism, the fact that every test run uses a different query, was what Maxwell called a killer feature. Because that's how real users search. Not with the same string every time.
For validating AI outputs, Spur uses sentiment analysis rather than string matching, understanding whether a response is correct, helpful, and on-brand, rather than just checking whether it contains a specific word. That made testing Ava possible in a way that no traditional tool could achieve.
Within the first week, Maxwell wrote over 150 tests. Within the first month, Wander had 80%+ coverage and 500+ tests running daily. QA cycles dropped from days to minutes.
The Bug
Ava was flagging legitimate travel queries as spam. Every user asking about booking was being blocked.
This is the critical bug Spur caught and it's the kind that only an intelligent testing tool could find. Wander's AI concierge Ava was incorrectly classifying genuine booking inquiries as spam. Users asking natural questions about accommodations were being silently blocked from completing their bookings.
There was no string to check. No specific error message to look for. The only way to catch this was to simulate real conversations, the kind a real traveller might have, and evaluate whether Ava's responses made sense. That's exactly what Spur did.
Without Spur, this bug would have reached production. Guests would have hit a wall mid-booking, seen no explanation, and likely gone elsewhere. For a luxury travel product, that's not just a UX problem, it's a revenue problem.
The Results
20× release velocity, $750K in QA spend avoided and one engineer who can now do a teams job.
Nathan describes it simply: Spur allowed them to iterate and ship with confidence. 20× faster by release count, because the bottleneck was QA, and QA is now largely automated.
Maxwell, as the lone QA engineer on the team, effectively became a team of 50+ by deploying Spur's agents across search, booking, and AI interaction flows. 500+ tests running daily. Issues caught before they reach production and feedback in minutes.
"Spur has significantly improved Wander's testing capabilities. It has allowed us to iterate and ship so much faster with confidence."
The financial framing is also striking: $750K in avoided QA spend, and $10M+ in revenue-at-risk bugs caught before production. For a luxury travel platform where a single broken booking flow during peak season is expensive, that second number matters.

20x
Increase in release velocity
$750K
Annual QA spend avoided
80%+
Test coverage achieved within the first month


Key Insights
Wander's product generates different outputs every time, AI search results, AI concierge conversations, natural language interactions that no two users experience the same way. Traditional testing tools weren't built for that. Spur was. One engineer, 500+ tests daily, and the confidence to ship 20× faster, because the QA finally matched the product.










